数据仓库和数据挖掘技术
信息时代的信息处理分为事务型处理和信息型处理两大类。
事务型处理即通常所说的业务操作处理,如查询或修改。
信息型处理即对信息进行进一步的分析,通常必须访问大量的历史数据才能完成。
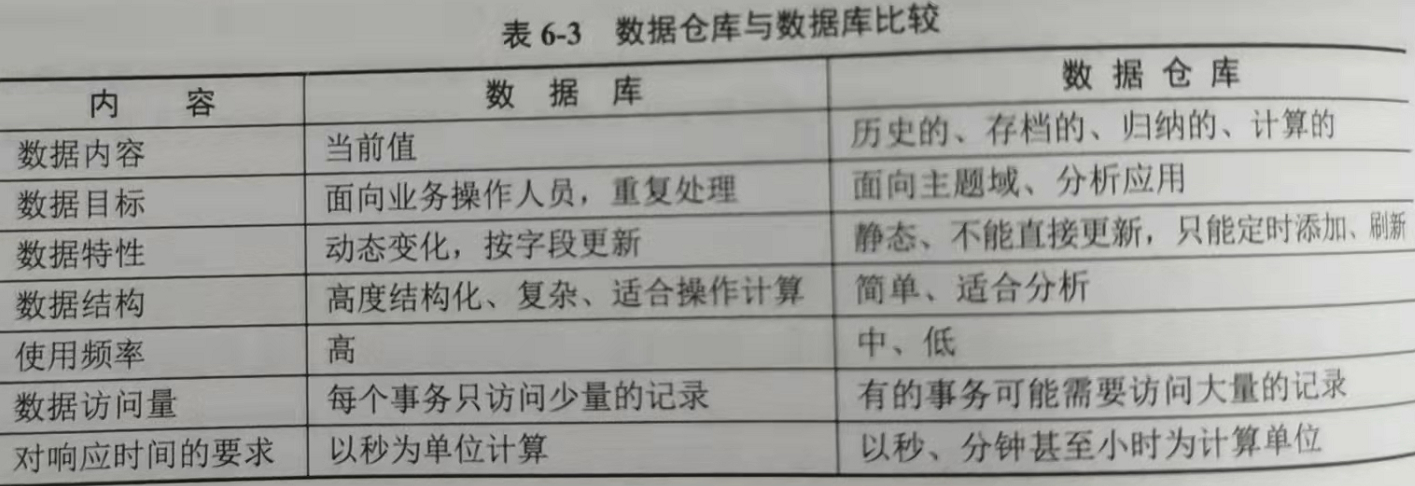
数据仓库
OLTP,On-Line Transaction Processing,即联机事务处理
为了能满足管理人员的决策分析需要,在数据库基础上产生了能满足决策分析需要的数据环境,即数据仓库,Data Warehouse(DW)。

数据仓库基本特征
- 面向主题的:主题就是一些数据集合。如“产品”、“客户”等主题。
- 数据是集成的:将分散于各处的数据进行抽取、筛选、清理和综合。
- 数据是相对稳定的:通常只进行查询操作。
- 数据是反映历史变化的:即随时间进行新增、删除以及重新组合。
数据仓库的数据模式
包括星型模式、雪花模式、事实星型模式。
数据仓库中的数据通常是多维的:包括维属性、度量属性。包括多维数据的表,称为事实表。
维属性通常是一些短的标识,作为参照其他表的外码。
事实表、多维表,以及从事实到多维表的参照外码的模式,称为星型模式。
在星型模式基础上,含有多级维表的,称为雪花模式。
如果一个数据仓库包含多个事实表,则称为事实星型模式。
数据仓库的体系结构
三层体系结构:
- 底层为数据仓库服务器:通常是一个关系数据库系统。
- 中间层为OLAP(Online analytical processing,联机分析处理)服务器
- 顶层为前端工具。即查询和报表工具、分析工具、数据挖掘工具。
从结构的角度看有三种数据仓库模型:企业仓库、数据集市和虚拟仓库。
数据挖掘
从海量数据库中挖掘信息的技术,称为数据挖掘( Data Mining,DM )。
数据挖掘的分类
按照所挖掘的数据库分:关系型数据库的数据挖掘、数据仓库的数据挖掘、面向对象数据集的挖掘、空间数据库的挖掘、正文数据库和多媒体数据库的数据挖掘等。
按所发现的知识类别分:关联规则、特征描述、分类分析、聚类分析、趋势分析和偏差分析。
按所发现的知识抽象层次分:一般化知识、初级知识和多层次知识。
数据挖掘的三种基础技术是:海量数据搜集、强大的多处理器计算机、数据挖掘算法。
在数据挖掘中常用的技术有:
- 人工神经网络
- 决策树
- 遗传算法
- 近邻算法
- 规则推导
数据挖掘工具与传统数据分析工具的比较
数据挖掘与数据仓库的关系
略
数据挖掘技术的应用过程
数据挖掘过程一般需要经历以下几个阶段:
- 确定挖掘对象
- 准备数据
- 建立模型
- 数据挖掘
- 结果分析
- 知识应用
相关真题
2015年39题
数据挖掘的分析方法可以划分为关联分析、序列模式分析、分类分析和聚类分析四种。
如果需要一个示例库(该库中的每个元组都有一个给定的类标识)做训练集时,这种分析方法属于(39)。
(39)A.关联分析 B.序列模式分析 C.分类分析 D.聚类分析
【答案】C
也可以说,数据挖掘是一类深层次的数据分析。
无论采用哪种技术完成数据挖掘,从功能上可以将数据挖掘的分析方法划分为四种即关联分析、序列模式分析、分类分析和聚类分析。
- ①关联分析(Associations):目的是为了挖掘出隐藏在数据间的相互关系。若设R={A1,A2,...,AP}为{0,1}域上的属性集,r为R上的一个关系,关于r的关联规则表示为X→B,其中X∈R,B∈R,且X∩B=¤。关联规则的矩阵形式为:矩阵r中,如果在行X的每一列为1,则行B中各列趋向于为1。在进行关联分析的同时还需要计算两个参数,最小置信度(Confidence)和最小支持度(Support)。前者用以过滤掉可能性过小的规则,后者则用来表示这种规则发生的概率,即可信度。
- ②序列模式分析(Sequential Patterns):目的也是为了挖掘出数据之间的联系,但它的侧重点在于分析数据间的前后关系(因果关系)。例如,将序列模式分析运用于商业,经过分析,商家可以根据分析结果发现客户潜在的购物模式,发现顾客在购买一种商品的同时经常购买另一种商品的可能性。在进行序列模式分析时也应计算置信度和支持度。
- ③分类分析(Classifiers):首先为每一个记录赋予一个标记(一组具有不同特征的类别),即按标记分类记录,然后检查这些标定的记录,描述出这些记录的特征。这些描述可能是显式的,如一组规则定义;也可能是隐式的,如一个数学模型或公式。
- ④聚类分析(Clustering):聚类分析法是分类分析法的逆过程,它的输入集是一组未标定的记录,即输入的记录没有作任何处理。目的是根据一定的规则,合理地划分记录集合,并用显式或隐式的方法描述不同的类别。
在实际应用的DM系统中,上述四种分析方法有着不同的适用范围,因此经常被综合运用。