数据库定义
SQL支持的基本域类型如下:
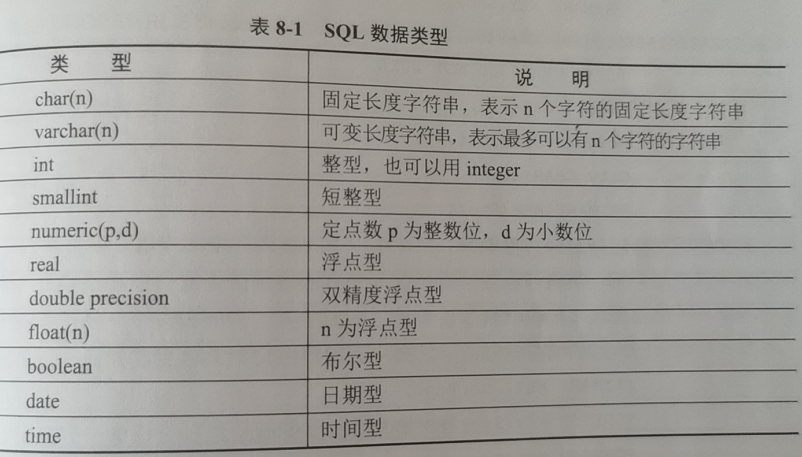
- numeric(p,d)等价 Decimal(p,s)
- real 尾数精度7
- float 尾数精度16
- double precision 尾数精度16
以上是教材中的定义,并不完整。还包括TIMESTAMP、BINARY 等数据类型。
创建表
-- https://dev.mysql.com/doc/refman/8.0/en/create-table.html
CREATE TABLE [if not exist] table_name (
字段1 数据类型 [列级完整性约束条件] [ 索引] [注释]
[,字段2 数据类型 [列级完整性约束条件] [ 索引] [注释] ]
[,表级完整性约束条件]
) [表类型 字符集 注释];
-- 列级完整性约束有 NULL 空,UNIQUE 取值唯一,如 NOT NULL UNIQUE 表示取值唯一,不能为空By default, tables are created in the default database, using the InnoDB storage engine.
An error occurs if the table exists, if there is no default database, or if the database does not exist.
示例:
-- 示例1
CREATE TABLE t1 (
c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
c2 VARCHAR(100),
c3 VARCHAR(100) )
ENGINE=NDB
COMMENT="NDB_TABLE=READ_BACKUP=0,PARTITION_BALANCE=FOR_RP_BY_NODE";
-- 示例2 单个字段主键
CREATE TABLE IF NOT EXISTS t2(
c1 varchar(8) NOT NULL PRIMARY KEY,
c2 varchar(50) NOT NULL,
c3 varchar(25) NOT NULL
);
-- 示例3 单个字段主键
CREATE TABLE IF NOT EXISTS t3(
c1 varchar(8) NOT NULL,
c2 varchar(50) NOT NULL,
c3 varchar(25) NOT NULL,
PRIMARY KEY (c1)
);
-- 示例4 多个主键
CREATE TABLE IF NOT EXISTS t4(
c1 varchar(8) NOT NULL,
c2 varchar(50) NOT NULL,
c3 varchar(25) NOT NULL,
PRIMARY KEY (c1,c2)
);
-- 示例5 外键约束
CREATE TABLE IF NOT EXISTS t5(
c1 varchar(8) NOT NULL,
c2 varchar(50) NOT NULL,
c3 varchar(25) NOT NULL,
PRIMARY KEY (c1),
FOREIGN KEY (c1) REFERENCES t3(c1)
);
-- 示例6 索引约束
-- INDEX和KEY参数用来指定字段为索引的
-- 索引可以添加关键字,如 UNIQUE INDEX 唯一索引,FULLTEXT INDEX 全文索引等
CREATE TABLE IF NOT EXISTS t6(
c1 varchar(8) NOT NULL,
c2 varchar(50) NOT NULL,
c3 varchar(25) NOT NULL,
PRIMARY KEY (c1),
INDEX (c2)
);💯 常见的建表约束(Create Table Constraints)
- 列级(column level)约束:作用于某一列。
- 表级(table level)约束:作用于整个表。
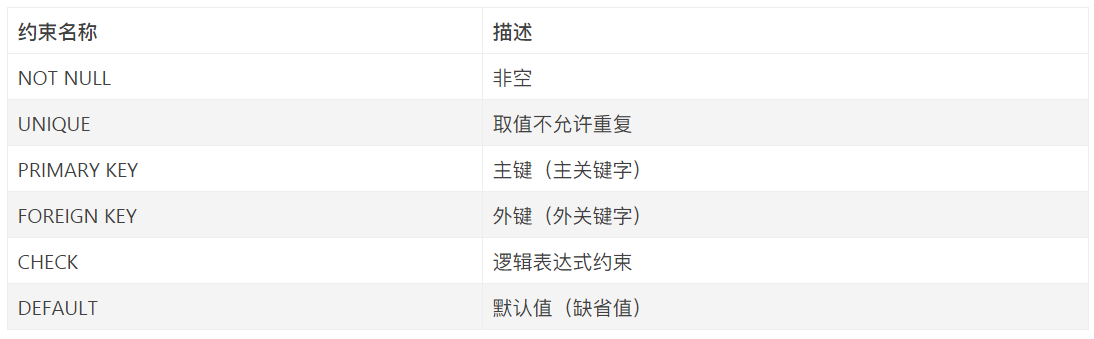
⚡️ P297页的 例8.1 需要掌握。

解析:

修改表和删除表
-- 修改表
ALTER TABLE table_name
[ ADD 新列名 数据类型 [完整性约束条件]]
[DROP 完整性约束]
[MODIFY 列名 数据类型 ]
-- 示例1: 例如 向供应商表S增加Zap邮政编码字段
-- 不论基本表中原来是否已有数据,新增的列一律为空
ALTER TABLE S ADD zap CHAR(6);
-- 示例2: 将status字段改为整型
ALTER TABLE S MODIFY status INT;
-- 删除表
DROP TABLE table_name创建删除索引
数据库中的索引与书籍的索引类似,在一本书中,利用索引可以快速查找所需信息。
索引使数据库程序无须对整个表进行扫描,就可以找到所需数据。
数据库的索引是某个表中一列或者若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
简言之:索引是对数据库表中一列或多列的值进行排序的一种结构。
索引的优缺点:
优点:
# 索引大大减小了服务器需要扫描的数据量,从而大大加快数据的检索速度,这也是创建索引的最主要的原因。
# 索引可以帮助服务器避免排序和创建临时表
# 索引可以将随机IO变成顺序IO
# 索引对于InnoDB(对索引支持行级锁)非常重要,因为它可以让查询锁更少的元组,提高了表访问并发性
# 关于InnoDB、索引和锁:InnoDB在二级索引上使用共享锁(读锁),但访问主键索引需要排他锁(写锁)
# 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
# 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
# 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
# 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
# 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
# 索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果需要建立聚簇索# 引,那么需要占用的空间会更大
# 对表中的数据进行增、删、改的时候,索引也要动态的维护,这就降低了整数的维护速度
# 如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
# 对于非常小的表,大部分情况下简单的全表扫描更高效;索引是建立在数据库表中的某些列的上面。
⚡️ 因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
应该创建索引的列
- 在经常需要搜索的列上,可以加快搜索的速度
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构
- 在经常用在连接(JOIN)的列上,这些列主要是一外键,可以加快连接的速度
- 在经常需要根据范围(<,<=,=,>,>=,BETWEEN,IN)进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的
- 在经常需要排序(order by)的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
不建议创建索引的列
- 对于那些在查询中很少使用或者参考的列不应该创建索引。若列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
- 对于那些只有很少数据值或者重复值多的列也不应该增加索引。 这些列的取值很少,例如性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 对于那些定义为text, image和bit数据类型的列不应该增加索引。 这些列的数据量要么相当大,要么取值很少。
- 当该列修改性能要求远远高于检索性能时,不应该创建索引。(修改性能和检索性能是互相矛盾的)
MySQL中常用的索引结构(索引底层的数据结构)有:B-TREE ,B+TREE ,HASH 等。
索引分聚集索引和非聚集索引。
创建索引
-- 方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
-- 方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL | CLUSTER ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
-- 方法三:ALTER TABLE 在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
--------------------------- 例如 ------------------------------
-- 创建普通索引
CREATE INDEX index_name ON table_name(col_name);
-- 创建唯一索引
CREATE UNIQUE INDEX index_name ON table_name(col_name);
-- 创建普通组合索引
CREATE INDEX index_name ON table_name(col_name_1,col_name_2);
-- 创建唯一组合索引
CREATE UNIQUE INDEX index_name ON table_name(col_name_1,col_name_2);
--- 修改索引
ALTER TABLE table_name ADD INDEX index_name(col_name);删除索引
-- 直接删除索引
DROP INDEX index_name ON table_name;
-- 修改表结构删除索引
ALTER TABLE table_name DROP INDEX index_name;查看索引信息
-- 查看索引信息(包括索引结构等)
show index from table_name;视图创建和删除
💯 视图不是真实存在的表,而是虚拟表。
视图是从一个或者多个基本表或视图中导出的表,其结构和数据是建立在对表的查询基础上的。
和真实的表一样,视图也包括几个被定义的数据列和多个数据行。
视图的创建和删除如下:
-- ----------------------创建视图---------------------------
CREATE VIEW 视图名(列表名)
AS SELECT 查询子句
[WITH CHECK OPTION]
-- 视图创建的规则
-- 1. 子查询可以是任意复杂的SELECT语句,但是不允许包含 order by 和 distinct
-- 2. WITH CHECK OPTION 表示对UPDATE、INSERT、DELETE 操作时保证更新、插入或删除的行满足视图中定义的谓词条件(即子查询中条件表达式)。
-- 3. 组成视图的属性列名或全部省略或全部指定。
-- ----------------------删除视图---------------------------
DROP VIEW 视图名
-- 例如
DROP VIEW CS-STUDENT;P301例题:
